Why is Prompt Injection used in Attacks & Defenses?
Cybersecurity is abuzz with a new entrant making its presence felt through vulnerable attacks leading to compromised information. First up with the core AI technology, machine learning and large language models (LLMs) are quickly being added to many applications to expand the applications’ functionality. Duping Artificial intelligence has been the norm for the malicious threat actors worldwide. With cybercrime increasing at a staggering rate; it is essential to understand the novel entrants and learn to guard against them.
We all understand user prompts, but learning how prompt injections work will be interesting. Delving deeper into the realms of cybersecurity and getting to the core of this novel cyberattack will give us the insight to put up with it like a pro!
About Prompt Injection Attacks:
Prompt Injections are a type of cyberattack that involves manipulating a large language model (LLM) to produce an unintended response. These large language models are the foundation models; that are highly flexible machine learning models trained on large datasets. Prompt injection attack is done by injecting malicious inputs into the model, which can lead to the disclosure of sensitive information or system malfunctions. Hackers trick an LLM into divulging its system prompt. Malicious threat actors may use it as a template to craft malicious input. If hackers’ prompts look like the system prompt, the LLM is more likely to comply. It has been ranked in the Top 10 OWASP threats for LLMs as well.
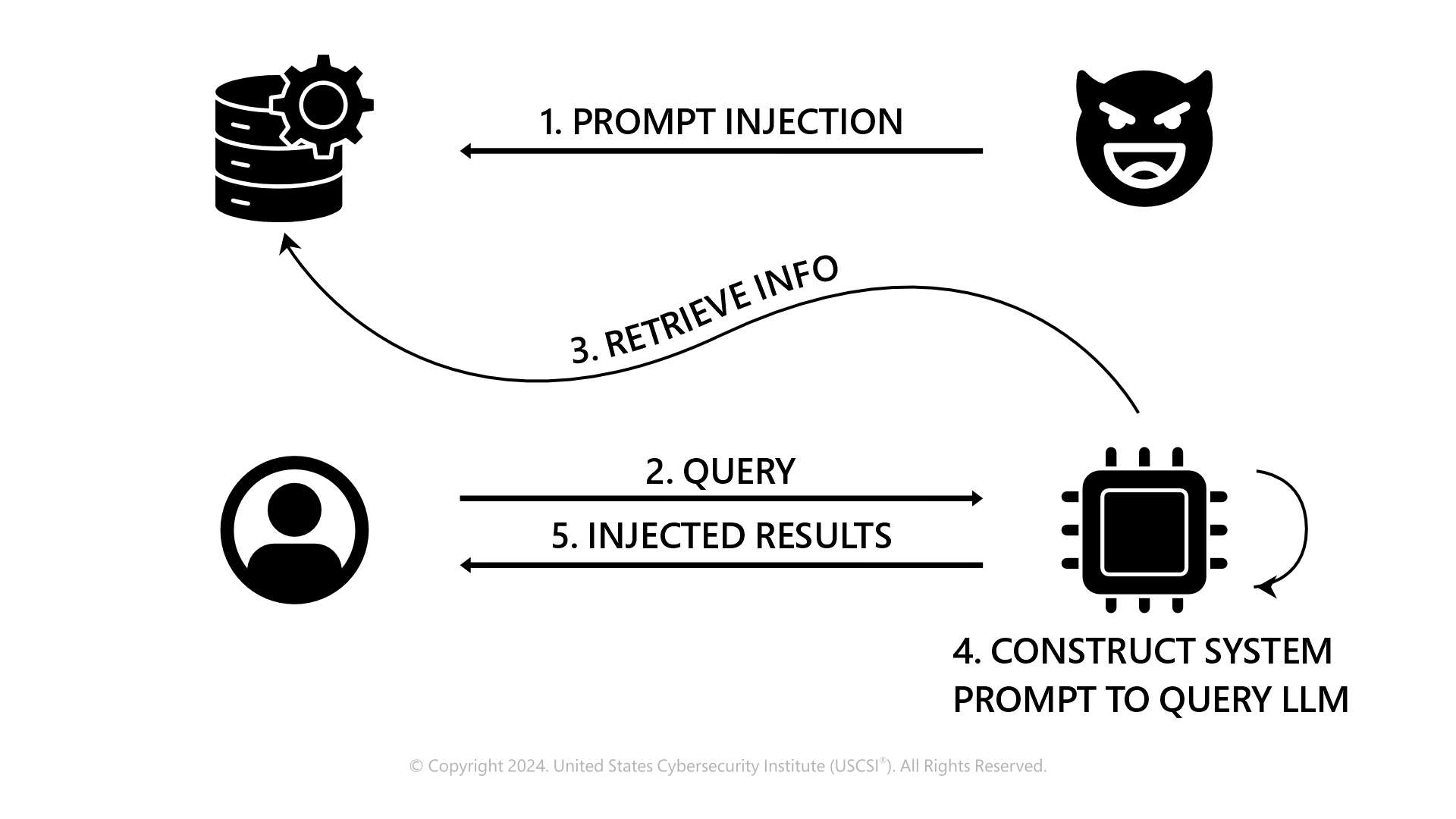
The above representation throws light on the way an attacker deduces and cracks the prompt injection attack. Visibly, they can potentially impact the results of any or all the legitimate application users’ interactions with the application. An attacker may target specific items of interest, specific users, or even corrupt significant portions of the data by overwhelming the knowledge base with misinformation.
Example:


- Jailbreaking- Makes a target chatbot grant users the freedom to ask any question they would like and has been seen with Do Anything Now (DAN) and Developer Mode Prompts.
- Obfuscation- Malicious attackers try to evade filters by replacing certain words (tokens) that would trigger filters with synonyms or modify them to include a typo.
- Payload Splitting- This breaks down the adversarial input into multiple parts and then gets the LLMs to combine and execute them.
- Virtualization- Involves creating a scene or scenario for the AI to bypass the model’s filtering mechanism and execute harmful actions.
- Code Injection- A prompt hacking technique where the attacker tricks the LLM into running unauthorized code typically written in Python.
Risks:

When developing a testing strategy for large language models (LLMs), it is imperative to consider these potential risks and compromises as integral components of the system rather than third-party black boxes. Testing depends on the context, therefor it is crucial to carefully consider potential threats to your system during the preparation stage itself.
Mitigation Measures:
- PRE-FLIGHT PROMPT CHECK
As an ‘Injection test’; it uses the user input in a special prompt designed to detect when the user input is manipulating the prompt logic.
- PARAMETERIZATION
Structured queries are introduced to incorporate parameterization, converting system prompts and user data into specialized formats for efficient model training.
- INPUT VALIDATION AND SANITIZATION
Input validation involves ensuring that user input complies with the correct format, while sanitization entails removing potentially malicious content from the input to prevent security vulnerabilities.
- OUTPUT VALIDATION
It is the process of blocking or sanitizing the output generated by LLMs to ensure it does not contain infected content.
- BUILD INTERNAL PROMPTS ROBUSTNESS
Embedding safeguards directly into the system prompts that guide AI applications. delimiters are unique character strings that distinguish system prompts and user inputs.
- CONTINUOUS LARGE LANGUAGE MODEL TESTING
It involves simulating diverse attack scenarios to assess the model’s response and periodic updates and model retraining to enhance their resilience.
- MONITOR AND DETECT ANOMALIES
This aids in swiftly spotting and addressing prompt injection threats by analyzing user behavior for deviations.
- TIMELY HUMAN INTERVENTION
Expert cybersecurity specialists must be designated by corporations and businesses to safeguard systems from malicious cyberattacks. Their timely intervention is a must for a healthy business scenario.
- DETECT INJECTIONS
Training an injection classifier starts with assembling a novel dataset with widely varying prompts, including prompt injections and legitimate requests.
Final Word:
Understanding how large language models (LLMs) work and identifying the potential threats is of utmost importance. You must leverage key security principles that can significantly enhance the overall trust in the AI model. Hiring the nuanced cybersecurity professionals with the requisite cybersecurity courses will pave the way toward a safer and highly guarded security system organization-wide.